
A container is a lightweight unit of software that includes application code and all its dependencies such as binary code, libraries, and configuration files for easy deployment across different computing environments. Since a container is self-contained and includes all dependencies, the application it supports will run reliably across different computing environments.
Containers are used to get software to run reliably when moved from one computing environment to another (e.g., from a physical machine in a datacenter to a virtual machine (VM) in the public cloud).
Back in 2007, some Google engineers added features to the Linux kernel under the umbrella term cgroups; native and intrinsic to the kernel, these features provided functionality to limit and isolate the resources (CPU, memory, disk I/O, network, etc.) used by collections of processes. Leveraging these features allowed containers to appear – namely LXC (Linux Containers), an OS-level virtualization method for running multiple isolated Linux systems (containers) on a control host using a single Linux kernel.
In addition to the Cgroup resource control, functionality was provided for namespace isolation, as well as complete isolation of an application’s view of the operating environment, including process trees, networking, user IDs, and mounted file systems. In other words, a way of securely virtualizing an application was provided within the Linux Kernel itself without the need to spin-up a virtual machine (VM).
In traditional virtualization, each VM has its own OS. This means segregating applications by putting them in separate VMs has high overhead, as it involves spinning up the VM and resourcing it both in terms of time and hardware. In contrast, containers are very scalable and lightweight, and also very secure particularly, as they can only interact through defined interfaces. Often, containers are referred to as virtual environments (VE), and because it’s built into the kernel, there’s no emulation overhead and you get native performance.
There’s no single way of defining containers; and several genres extending LXC have evolved. Docker is probably the most-high profile; it abstracts the end-user a bit further and automates the process of defining containers, how they communicate, etc. There’s a useful FAQ on the Docker site that explains this further, including the container configuration and templating functionality. One of the key features is that Docker provides a mechanism to generate containers that are portable across different machines, although numerous other mechanisms to do this exist.
Once we have containers, we now have a solution to the problem of those in-application / “it works on MY machine” bugs; if an application is deployed within a container, its view of the world is always the same. The segregation/sandboxing means another application can’t overwrite the memory being used and so on. Containers can be useful for individual developers and managed/scripted on a small scale by numerous mechanisms. At scale, orchestration frameworks such as Kubernetes (K8s) are often leveraged to manage and leverage containers.
It also worth noting that whilst the Kubernetes framework (for orchestrating / managing containers) is open sourced, Docker is a proprietary product, acquired by Mirantis in 2019.
The term “container image” refers to the package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings. Container images become containers at runtime. Containers execute on a Container engine. There are different container engines available today. The popular ones include:
When it comes to defining virtual machines, the name says it all – machines (servers or desktops) that have been virtualized. The operating system, applications, and services are all bundled into a single image that is accessed via a hypervisor, built on virtualized hardware.
Containers, such as Docker, are slightly different. Containers typically contain a single app or microservice, alongside the various runtime libraries they need to run. Importantly, they do not contain an operating system and they do not need a hypervisor to run – they run on a shared engine kernel, thus effectively operating on bare metal.
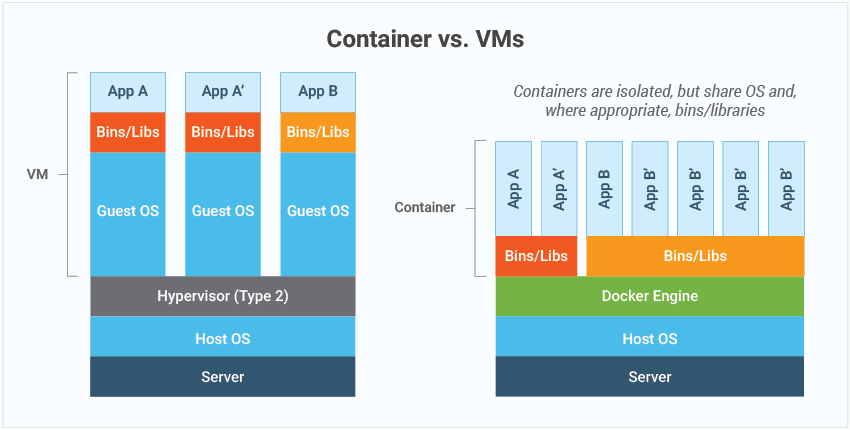
More details on the differences are covered in, Containers vs VM & Virtual Machines | eG Innovations, information on when you may choose to use Containers vs. Virtual Machines (VM) is also covered.
Containers are strictly defined, and as such, how they can communicate can be very tightly controlled and limited, so applications can be built for very specific tasks, which are only allowed to communicate with a very restricted audience. This type of architecture allows for microservices, which are inherently very secure and scalable. Containers support small, very specific applications which can do very bespoke tasks and provide very specific services (e.g., order a bank statement for a customer). Microservice architectures have a vast array of benefits: low attack surface, so it’s secure; clearly defined functionality, so ownership and maintenance can be easier.
There are of course security considerations around containers particularly when used at scale and there are some best practices to enhance container security around:
Popular monitoring choices for gaining visibility into containers include: Prometheus, Grafana, Datadog, eG Enterprise, New Relic, Dynatrace, Sysdig Monitor, AppDynamics, Instana, Splunk, Elastic Stack (Elasticsearch, Logstash, Kibana) and more.
Some of these are commercial products with enterprise support packages available and some are open-source / freeware options. The pros and cons of choosing open-source monitoring tools (including some of those specifically mentioned above) are covered, here: Top Freeware and Open-source IT Monitoring Tools.
A good container monitoring solution will allow monitoring in production and will auto-deploy monitoring within automation and orchestration frameworks.



